|
I'm a polymath research scientist and manager at NVIDIA, where I represent ADLR's (Applied Deep Learning Research) audio team. ADLR–Audio focuses on generative models with intelligence in audio understanding and synthesis, with occasional explorations in vision. I am passionate about generative modeling, machine perception and machine
improvisation. Over the years, I have had the opportunity to collaborate
with fantastic researchers and co-invent
Fugatto,
Audio Flamingo,
OMCAT,
ETTA,
Koel-TTS,
P-Flow,
the RAD* family of models with the One Aligner To Rule Them All,
Flowtron and
WaveGlow. During my PhD at UC Berkeley I was advised mainly by Prof. Sanjit Seshia and Prof. Edmund Campion and my research focused on machine listening and improvisation. At UC Berkeley, I was part of the TerraSwarm Research Center, where I worked on problems related to adversarial attacks and verified artificial intelligence. During Fall 2016 I was a Research Intern at Gracenote in Emeryville, where I worked on audio classification using Deep Learning. Previously I was a Scientist Intern at Pandora in Oakland, where I investigated segments and scores that describe novelty seeking behavior in listeners. Before coming to Berkeley, I completed a master's in Computer Music from HMDK Stuttgart in Germany and a bachelor's in Orchestral Conducting from UFRJ in Brazil. |

|
|
|
paper |
website |
abstract |
bibtex
Fugatto is a versatile audio synthesis and transformation model capable of following free-form text instructions with optional audio inputs. While large language models (LLMs) trained with text on a simple next-token prediction objective can learn to infer instructions directly from the data, models trained solely on audio data lack this capacity. This is because audio data does not inherently contain the instructions that were used to generate it. To overcome this challenge, we introduce a specialized dataset generation approach optimized for producing a wide range of audio generation and transformation tasks, ensuring the data reveals meaningful relationships between audio and language. Another challenge lies in achieving compositional abilities -- such as combining, interpolating between, or negating instructions -- using data alone. To address it, we propose ComposableART, an inference-time technique that extends classifier-free guidance to compositional guidance. It enables the seamless and flexible composition of instructions, leading to highly customizable audio outputs outside the training distribution. Our evaluations across a diverse set of tasks demonstrate that Fugatto performs competitively with specialized models, while ComposableART enhances its sonic palette and control over synthesis. Most notably, we highlight our framework's ability to execute emergent sounds and tasks -- sonic phenomena that transcend conventional audio generation -- unlocking new creative possibilities.
@misc{fugatto2025,
title={Fugatto},
author={Fugatto Team},
note={ICLR 2025, available at \url{https://fugatto.github.io/}}
}
|
|
|
|
arXiv |
abstract |
bibtex
Large Language Models (LLMs) have made significant strides in text generation and comprehension, with recent advancements extending into multimodal LLMs that integrate visual and audio inputs. However, these models continue to struggle with fine-grained, cross-modal temporal understanding, particularly when correlating events across audio and video streams. We address these challenges with two key contributions: a carefully curated benchmark and model, called OCTAV and OMCAT respectively. OCTAV (Omni Context and Temporal Audio Video) is a benchmark capturing event transitions across audio and video. Second, OMCAT (Omni Context Aware Transformer) is a powerful model that leverages RoTE (Rotary Time Embeddings), an innovative extension of RoPE, to enhance temporal grounding and computational efficiency in time-anchored tasks.Our model demonstrates state-of-the-art performance on Audio-Visual Question Answering (AVQA) tasks and the OCTAV benchmark, showcasing significant gains in temporal reasoning and cross-modal alignment, as validated through comprehensive experiments and ablation studies. Both the OCTAV benchmark and the code will be made publicly available.
@article{goel2024omcat,
title={OMCAT: Omni context aware transformer},
author={Goel, A and Sapra, K and Le, M and Valle, R and Tao, A and Catanzaro, B},
journal={arXiv preprint arXiv:2410.12109},
year={2024}
}
|
|
arXiv |
abstract |
bibtex
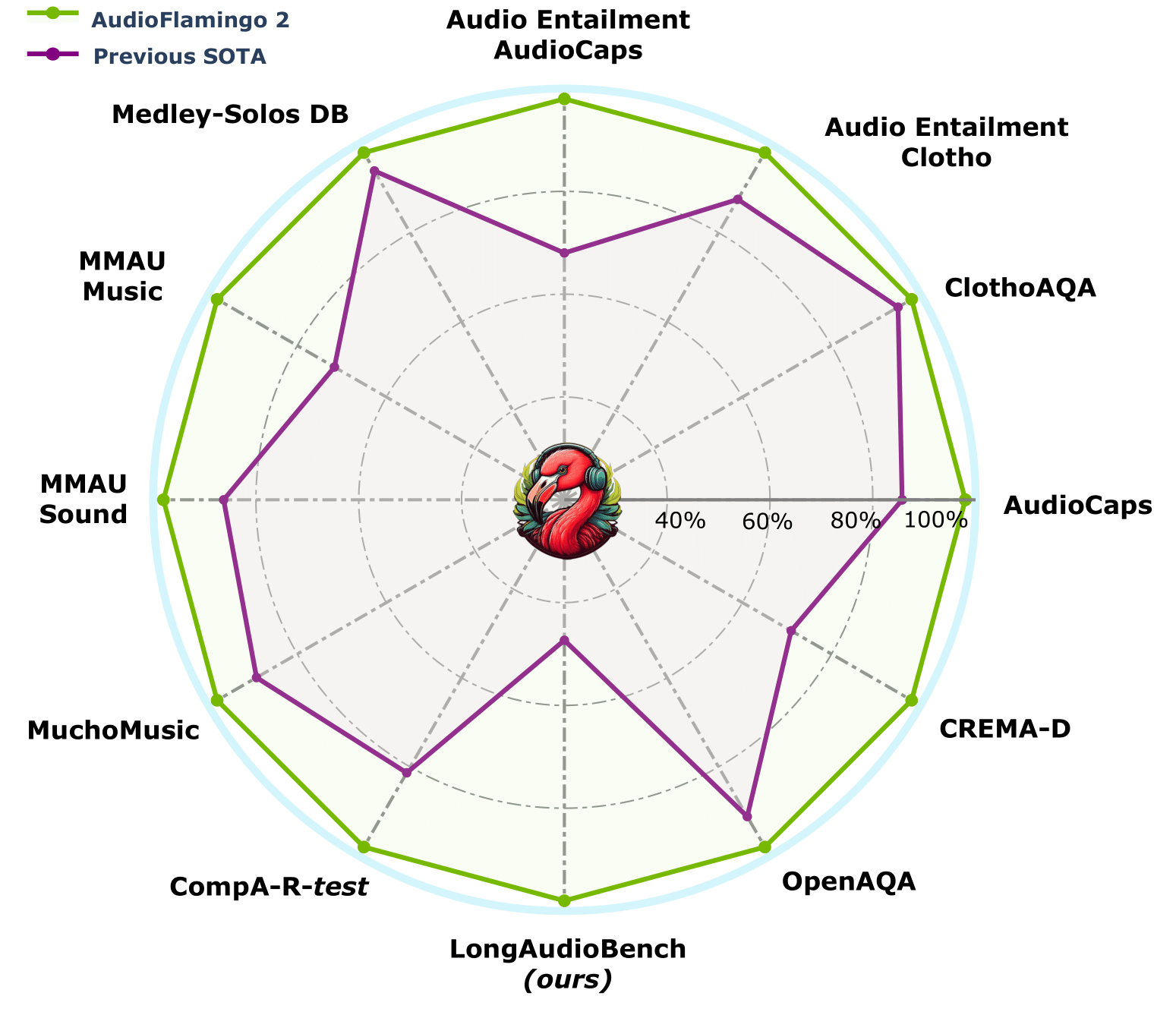
Understanding and reasoning over non-speech sounds and music are crucial for both humans and AI agents to interact effectively with their environments. In this paper, we introduce Audio Flamingo 2 (AF2), an Audio-Language Model (ALM) with advanced audio understanding and reasoning capabilities. AF2 leverages (i) a custom CLAP model, (ii) synthetic AQA data for fine-grained audio reasoning, and (iii) a multi-stage curriculum learning strategy. AF2 achieves state-of-the-art performance with only a 3B parameter small language model, surpassing large open-source and proprietary models across 20+ benchmarks. Next, for the first time, we extend audio understanding to long audio segments (30 secs - 5 mins) and propose LongAudio, a large and novel dataset for training ALMs on long audio captioning and question-answering tasks. Fine-tuning AF2 on LongAudio leads to exceptional performance on our proposed LongAudioBench, an expert annotated benchmark for evaluating ALMs on long audio understanding capabilities. We conduct extensive ablation studies to confirm the efficacy of our approach. All code and data will be open-sourced.
@article{kong2024audio,
title={Audio Flamingo: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities},
author={Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, Bryan Catanzaro},
journal={},
year={2025}
}
|
|
arXiv |
abstract |
bibtex
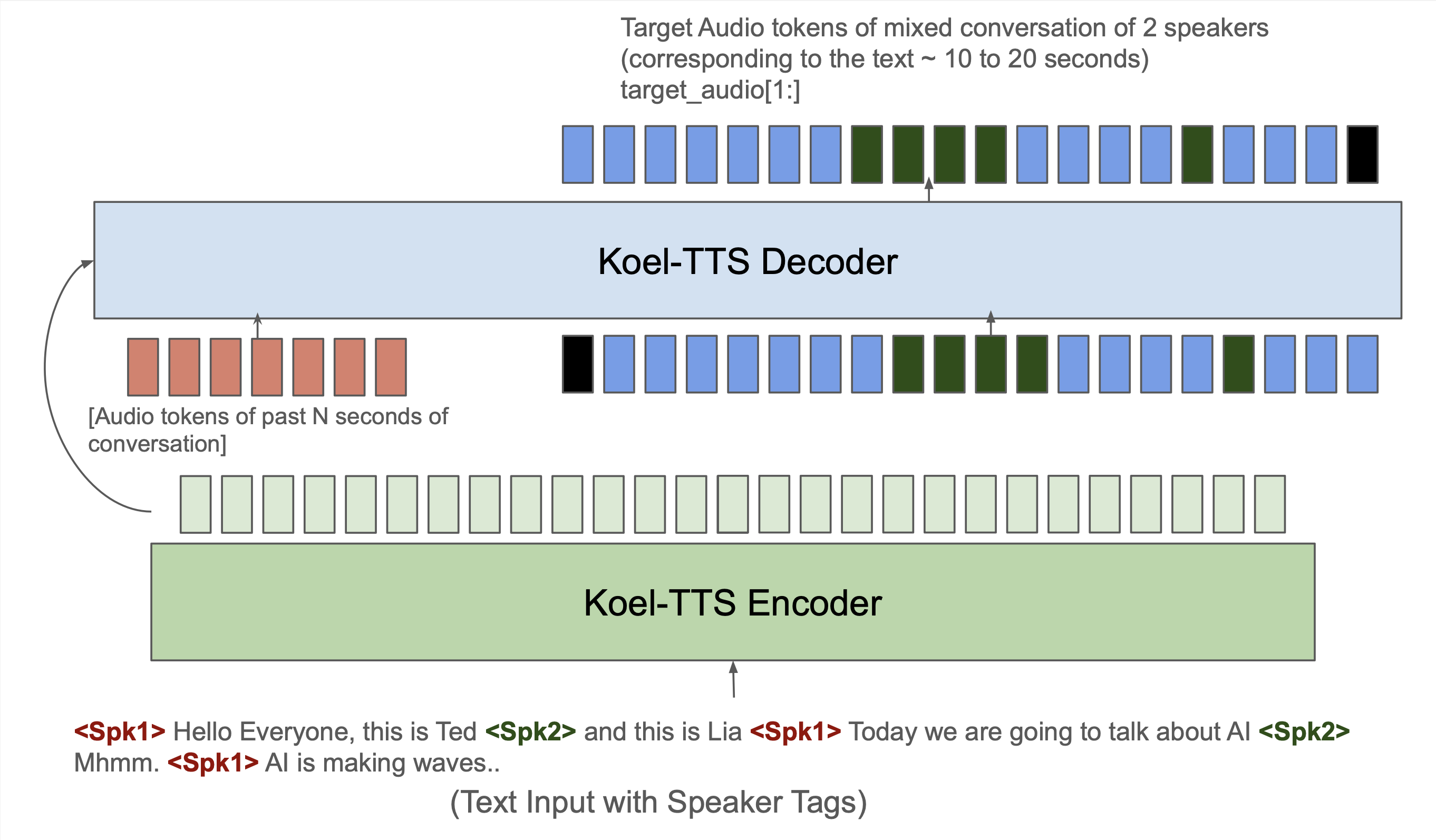
While autoregressive speech token generation models produce speech with remarkable variety and naturalness, their inherent lack of controllability often results in issues such as hallucinations and undesired vocalizations that do not conform to conditioning inputs. We introduce Koel-TTS, a suite of enhanced encoder-decoder Transformer TTS models that address these challenges by incorporating preference alignment techniques guided by automatic speech recognition and speaker verification models. Additionally, we incorporate classifier-free guidance to further improve synthesis adherence to the transcript and reference speaker audio. Our experiments demonstrate that these optimizations significantly enhance target speaker similarity, intelligibility, and naturalness of synthesized speech. Notably, Koel-TTS directly maps text and context audio to acoustic tokens, and on the aforementioned metrics, outperforms state-of-the-art TTS models, despite being trained on a significantly smaller dataset. Audio samples and demos are available on our website.
@article{hussain2025koelt,
title={Koel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance},
author={Hussain, S and Neekhara, P and Yang, X and Casanova, E and Ghosh, S and Desta, MT and ...},
journal={arXiv preprint arXiv:2502.05236},
year={2025}
}
|
|
website |
abstract |
bibtex
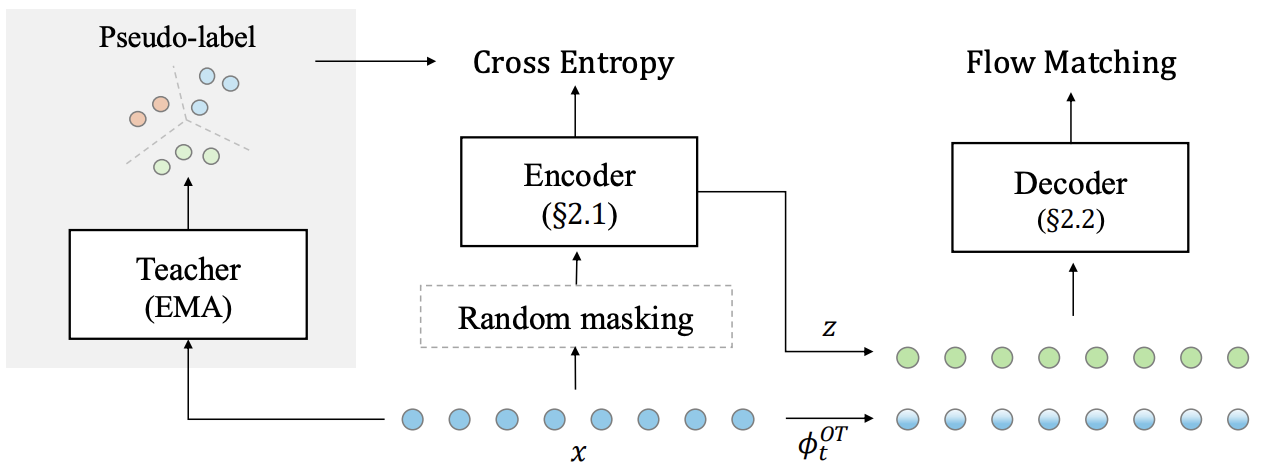
Pre-training and representation learning have been playing an increasingly important role in modern speech processing. Nevertheless, different applications have been relying on different foundation models, since predominant pre-training techniques are either designed for discriminative tasks or generative tasks. In this work, we make the first attempt at building a unified pre-training framework for both types of tasks in speech. We show that with the appropriate design choices for pre-training, one can jointly learn a representation encoder and generative audio decoder that can be applied to both types of tasks. We propose UniWav, an encoder-decoder framework designed to unify pre-training representation learning and generative tasks. On speech recognition, text-to-speech, and speech tokenization, UniWav achieves comparable performance to different existing foundation models, each trained on a specific task. Our findings suggest that a single general-purpose foundation model for speech can be built to replace different foundation models, reducing the overhead and cost of pre-training.
@misc{uniwav2025,
title={UniWav},
author={UniWav Team},
note={ICLR 2025, available at \url{https://research.nvidia.com/labs/twn/publication/iclr_2025_uniwav/}}
}
|
degraded bandwidth expanded |
arXiv |
abstract |
bibtex
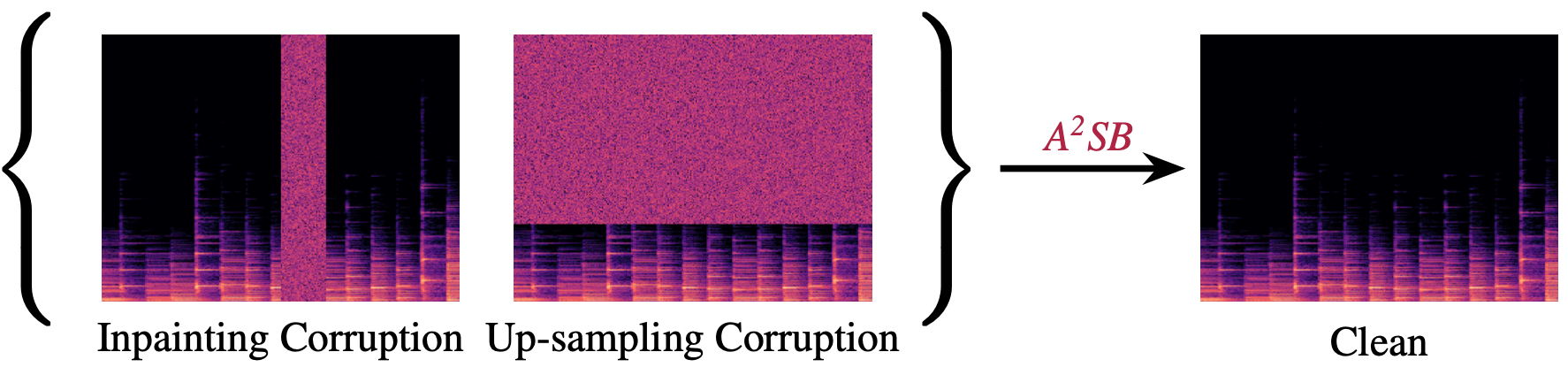
Audio in the real world may be perturbed due to numerous factors, causing the audio quality to be degraded. The following work presents an audio restoration model tailored for high-res music at 44.1kHz. Our model, Audio-to-Audio Schrodinger Bridges (A2SB), is capable of both bandwidth extension (predicting high-frequency components) and inpainting (re-generating missing segments). Critically, A2SB is end-to-end without need of a vocoder to predict waveform outputs, able to restore hour-long audio inputs, and trained on permissively licensed music data. A2SB is capable of achieving state-of-the-art bandwidth extension and inpainting quality on several out-of-distribution music test sets.
@article{kong2025a2sb,
title={A2SB: Audio-to-Audio Schrodinger Bridges},
author={Kong, Z and Shih, KJ and Nie, W and Vahdat, A and Lee, S and Santos, JF and Jukic, A and Valle, R and ...},
journal={arXiv preprint arXiv:2501.11311},
year={2025}
}
|
"A hip-hop track using sounds from a construction site—hammering nails as the beat, drilling sounds as scratches, and metal clanks as rhythm accents." |
arXiv |
abstract |
bibtex
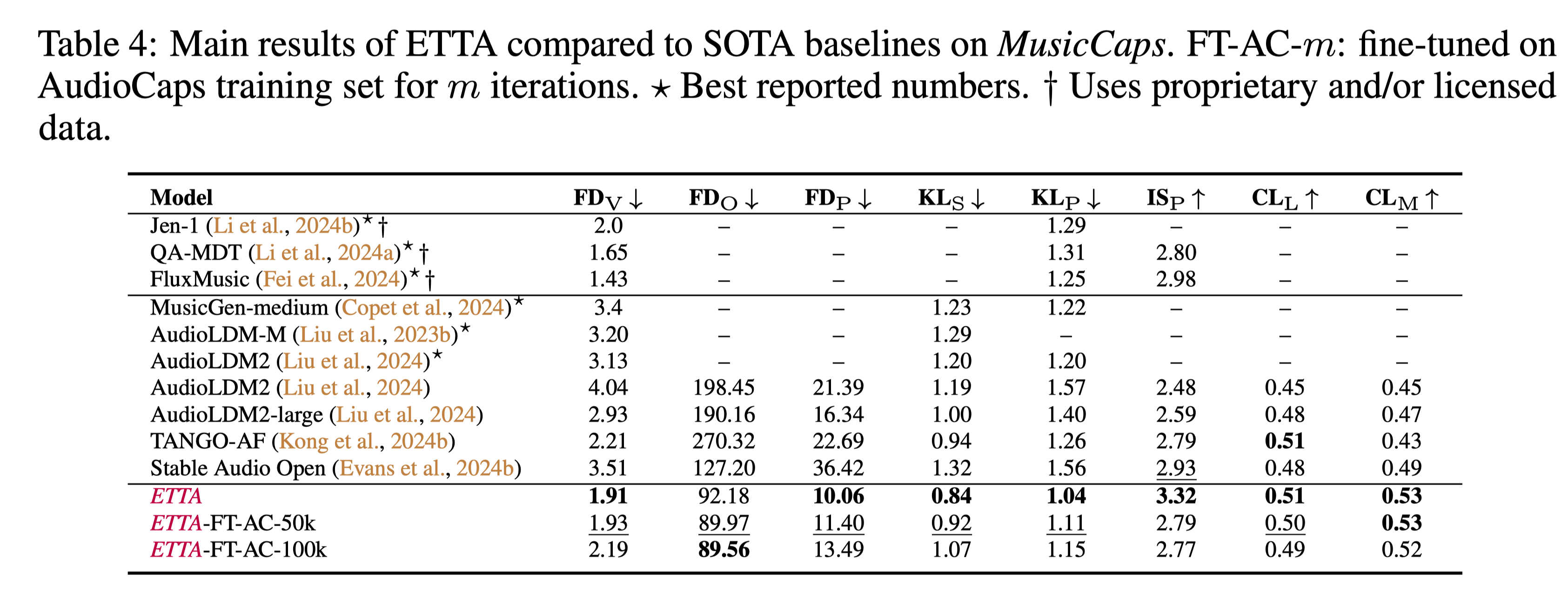
Recent years have seen significant progress in Text-To-Audio (TTA) synthesis, enabling users to enrich their creative workflows with synthetic audio generated from natural language prompts. Despite this progress, the effects of data, model architecture, training objective functions, and sampling strategies on target benchmarks are not well understood. With the purpose of providing a holistic understanding of the design space of TTA models, we set up a large-scale empirical experiment focused on diffusion and flow matching models. Our contributions include: 1) AF-Synthetic, a large dataset of high quality synthetic captions obtained from an audio understanding model; 2) a systematic comparison of different architectural, training, and inference design choices for TTA models; 3) an analysis of sampling methods and their Pareto curves with respect to generation quality and inference speed. We leverage the knowledge obtained from this extensive analysis to propose our best model dubbed Elucidated Text-To-Audio (ETTA). When evaluated on AudioCaps and MusicCaps, ETTA provides improvements over the baselines trained on publicly available data, while being competitive with models trained on proprietary data. Finally, we show ETTA's improved ability to generate creative audio following complex and imaginative captions -- a task that is more challenging than current benchmarks.
@article{lee2024etta,
title={ETTA: Elucidating the Design Space of Text-to-Audio Models},
author={Lee, S and Kong, Z and Goel, A and Kim, S and Valle, R and Catanzaro, B},
journal={arXiv preprint arXiv:2412.19351},
year={2024}
}
|

|
arXiv |
abstract |
bibtex
We introduce TangoFlux, an efficient Text-to-Audio (TTA) generative model with 515M parameters, capable of generating up to 30 seconds of 44.1kHz audio in just 3.7 seconds on a single A40 GPU. A key challenge in aligning TTA models lies in the difficulty of creating preference pairs, as TTA lacks structured mechanisms like verifiable rewards or gold-standard answers available for Large Language Models (LLMs). To address this, we propose CLAP-Ranked Preference Optimization (CRPO), a novel framework that iteratively generates and optimizes preference data to enhance TTA alignment. We demonstrate that the audio preference dataset generated using CRPO outperforms existing alternatives. With this framework, TangoFlux achieves state-of-the-art performance across both objective and subjective benchmarks. We open source all code and models to support further research in TTA generation.
@article{hung2024tangoflux,
title={TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization},
author={Hung, CY and Majumder, N and Kong, Z and Mehrish, A and Valle, R and Catanzaro, B and Poria, S},
journal={arXiv preprint},
year={2024}
}
|
|
pdf |
abstract |
bibtex
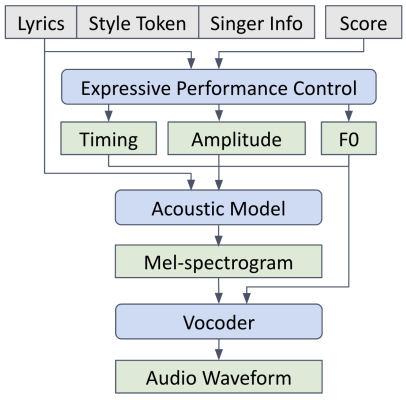
Singing Voice Synthesis (SVS) has significantly advanced with deep generative models, achieving high audio quality but still struggling with musicality, mainly due to the lack of performance control over timing, dynamics, and pitch, which are essential for music expression. Additionally, integrating data and supporting diverse languages and styles in SVS remain challenging. To tackle these issues, this paper presents ExpressiveSinger, an SVS framework that leverages a cascade of diffusion models to generate realistic singing across multiple languages, styles, and techniques from scores and lyrics. Our approach begins with consolidating, cleaning, annotating, and processing public singing datasets, developing a multilingual phoneme set, and incorporating different musical styles and techniques. We then design methods for generating expressive performance control signals including phoneme timing, F0 curves, and amplitude envelopes, which enhance musicality and model consistency, introduce more controllability, and reduce data requirements. Finally, we generate mel-spectrograms and audio from performance control signals with style guidance and singer timbre embedding. Our models also enable trained singers to sing in new languages and styles. Several listening tests reveal both musicality and controllability of our generated singing compared with existing works and human singing. We release the data for future research.
@inproceedings{dai2024expressivesinger,
title={Expressivesinger: Multilingual and multi-style score-based singing voice synthesis with expressive performance control},
author={Dai, S and Liu, MY and Valle, R and Gururani, S},
booktitle={Proc. 32nd ACM Multimedia},
pages={3229--3238},
year={2024}
}
|
|
arXiv |
abstract |
bibtex
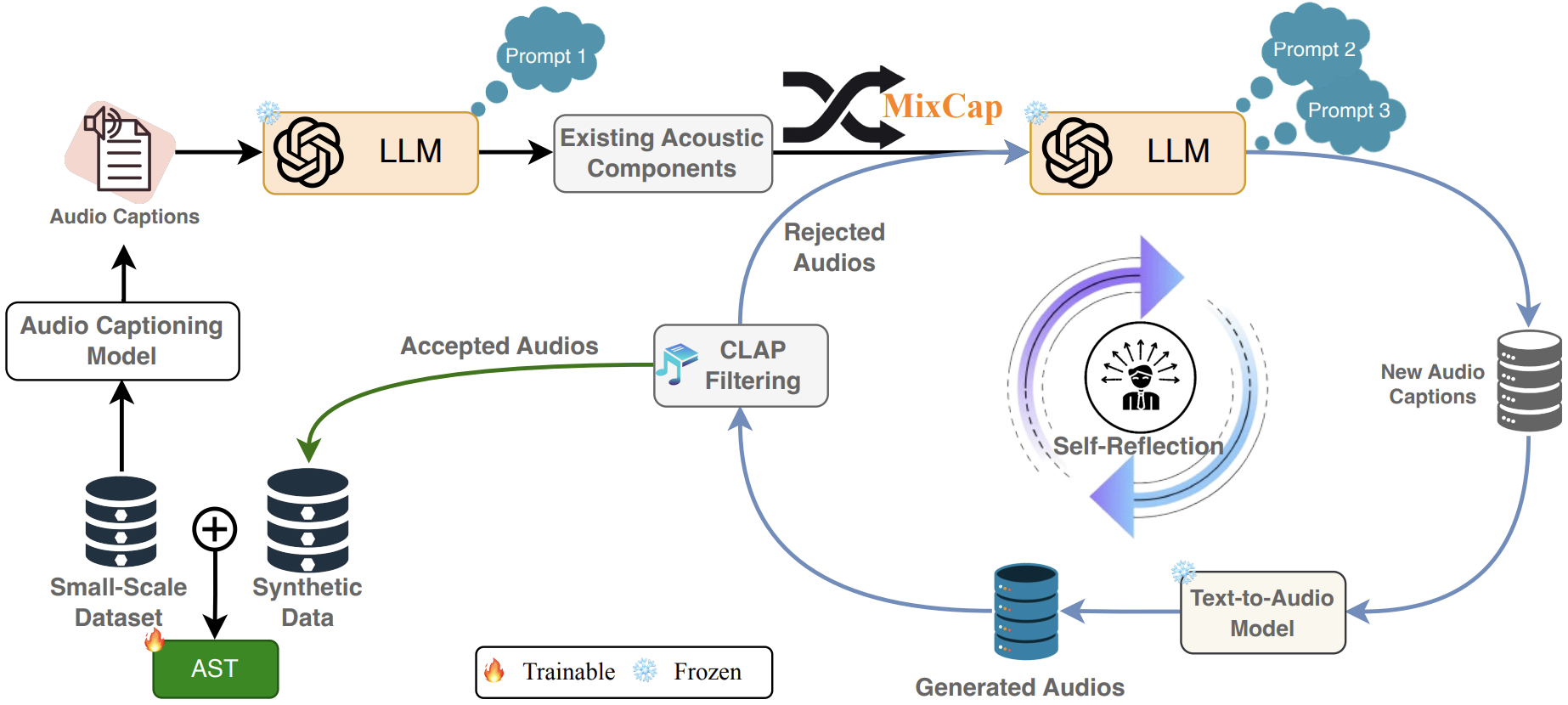
[Abstract placeholder for Synthio. Explanation of synthetic data augmentation for audio classification…]
@article{ghosh2024synthio,
title={Synthio: Augmenting Small-Scale Audio Classification Datasets with Synthetic Data},
author={Ghosh, S and Kumar, S and Kong, Z and Valle, R and Catanzaro, B and Manocha, D},
journal={arXiv preprint arXiv:2410.02056},
year={2024}
}
|
|
arXiv |
abstract |
bibtex
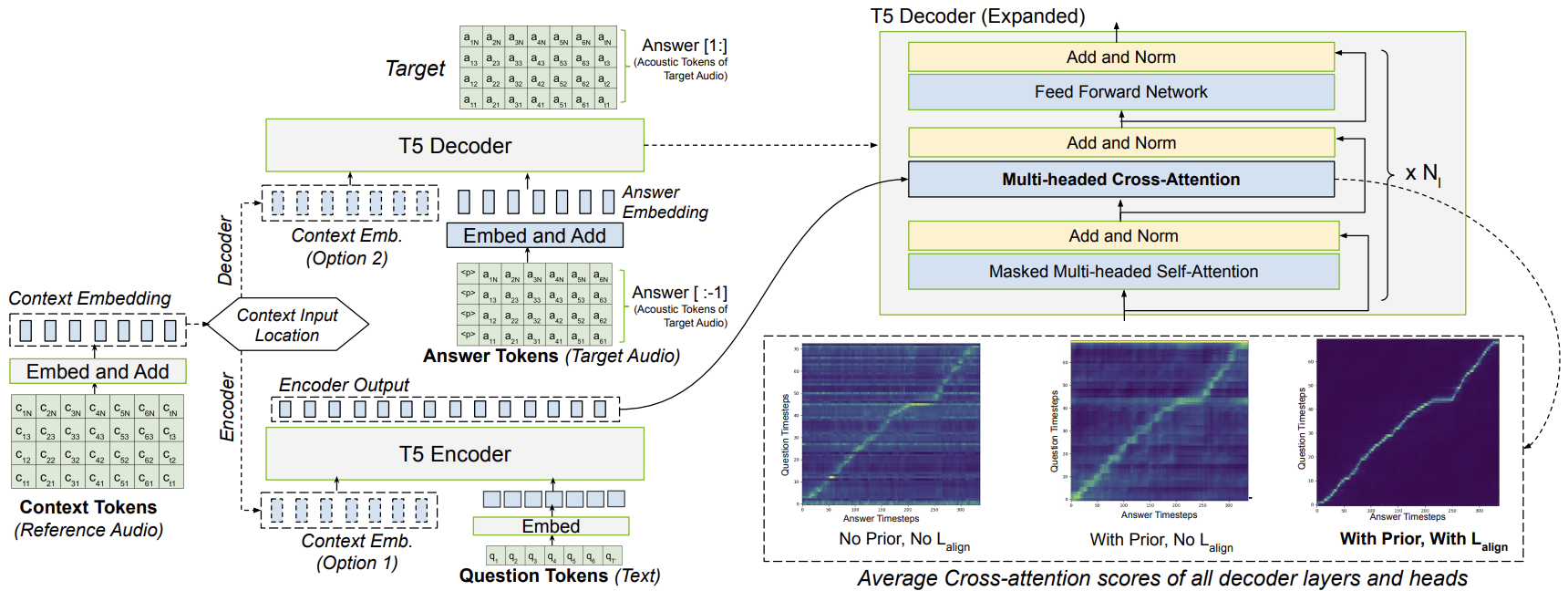
[Abstract placeholder for Robust Alignment. Discussion on learning monotonic alignments for LLM-based TTS…]
@article{neekhara2024robust,
title={Improving robustness of llm-based speech synthesis by learning monotonic alignment},
author={Neekhara, P and Hussain, S and Ghosh, S and Li, J and Valle, R and Badlani, R and Ginsburg, B},
journal={arXiv preprint arXiv:2406.17957},
year={2024}
}
|
|
|
arXiv |
abstract |
bibtex
In this paper, we propose Audio Flamingo, a novel audio language model with 1) strong audio understanding abilities, 2) the ability to quickly adapt to unseen tasks via in-context learning and retrieval, and 3) strong multi-turn dialogue abilities. We introduce a series of training techniques, architecture design, and data strategies to enhance our model with these abilities. Extensive evaluations across various audio understanding tasks confirm the efficacy of our method, setting new state-of-the-art benchmarks.
@article{kong2024audio,
title={Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities},
author={Kong, Zhifeng and Goel, Arushi and Badlani, Rohan and Ping, Wei and Valle, Rafael and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2402.01831},
year={2024}
}
|
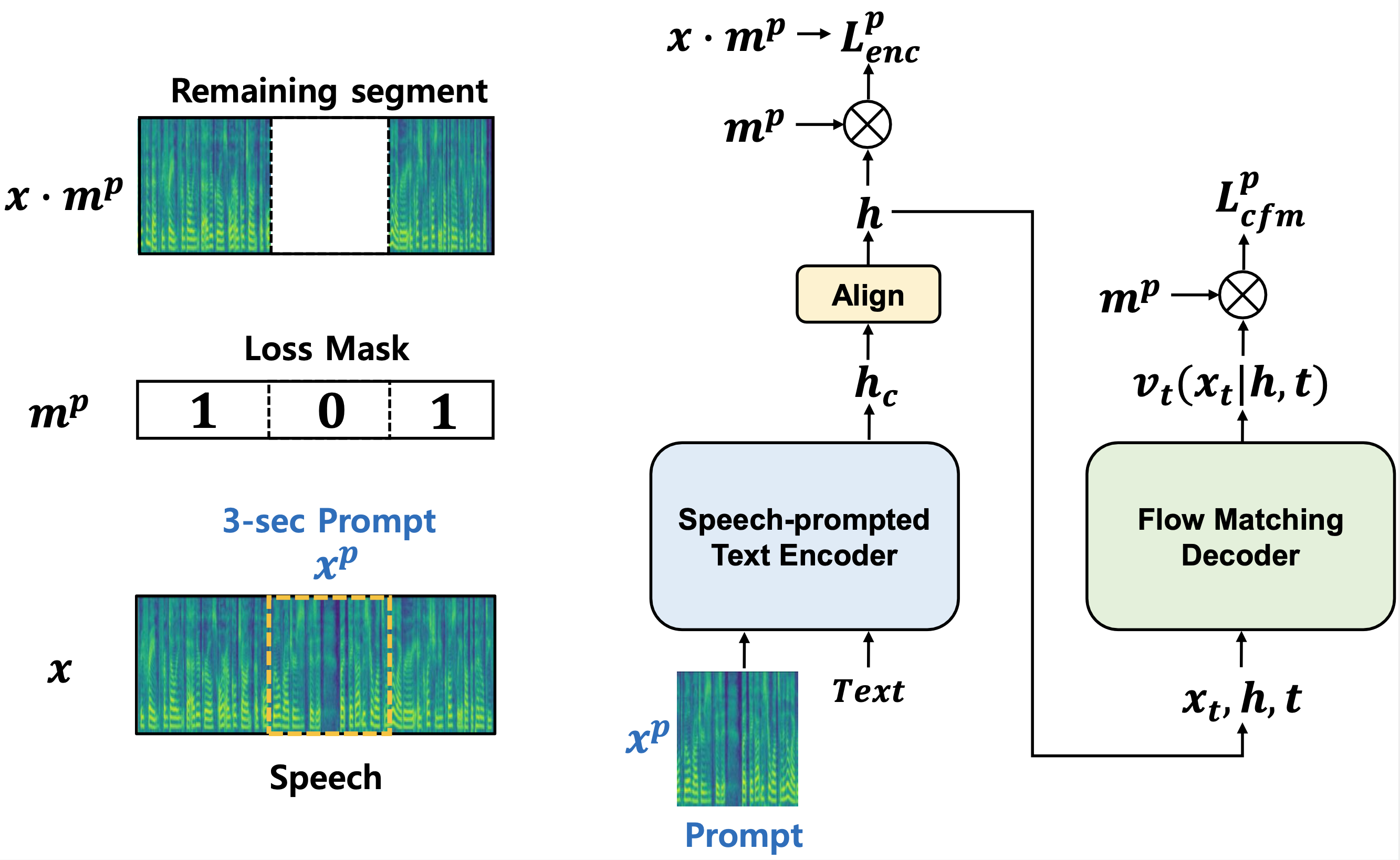 reference P-Flow |
pdf |
abstract |
bibtex
While recent large-scale neural codec language models have shown significant improvement in zero-shot TTS by training on thousands of hours of data, they suffer from drawbacks such as a lack of robustness, slow sampling speed similar to previous autoregressive TTS methods, and reliance on pre-trained neural codec representations. Our work proposes P-Flow, a fast and data-efficient zero-shot TTS model that uses speech prompts for speaker adaptation. P-Flow comprises a speech-prompted text encoder for speaker adaptation and a flow matching generative decoder for high-quality and fast speech synthesis. Our speech-prompted text encoder uses speech prompts and text input to generate speaker-conditional text representation. The flow matching generative decoder uses the speaker-conditional output to synthesize high-quality personalized speech significantly faster than in real-time. Unlike the neural codec language models, we specifically train P-Flow on LibriTTS dataset using a continuous mel-representation. Through our training method using continuous speech prompts, P-Flow matches the speaker similarity performance of the large-scale zero-shot TTS models with two orders of magnitude less training data and has more than 20$\times$ faster sampling speed. Our results show that P-Flow has better pronunciation and is preferred in human likeness and speaker similarity to its recent state-of-the-art counterparts, thus defining P-Flow as an attractive and desirable alternative.
|
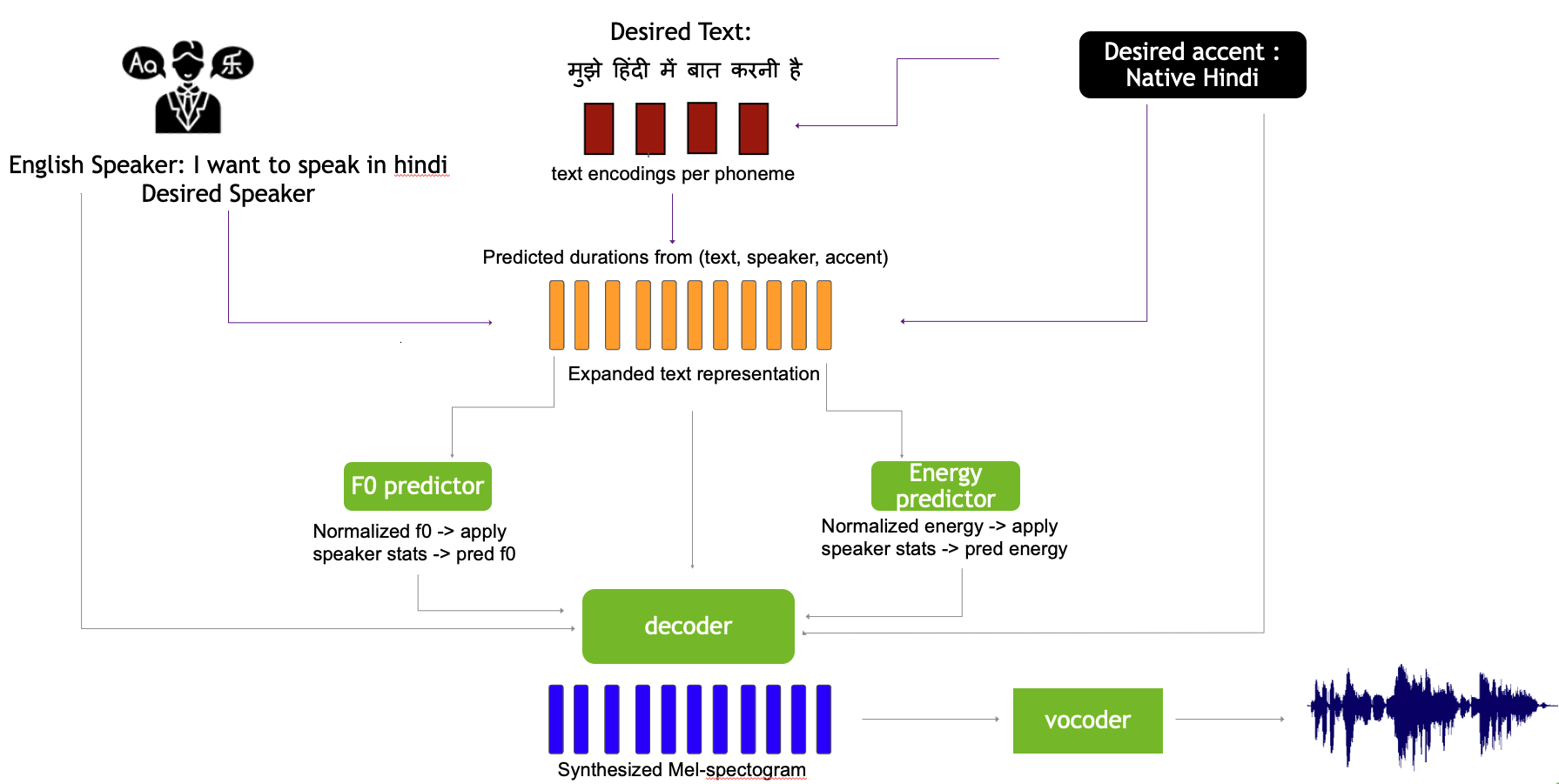 Seen (French) Unseen (German) Unseen (Hindi) Unseen (Spanish) |
pdf |
abstract |
bibtex |
arXiv |
code
We work to create a multilingual speech synthesis system which can generate speech with the proper accent while retaining the characteristics of an individual voice. This is challenging to do because it is expensive to obtain bilingual training data in multiple languages, and the lack of such data results in strong correlations that entangle speaker, language, and accent, resulting in poor transfer capabilities. To overcome this, we present a multilingual, multiaccented, multispeaker speech synthesis model based on RADTTS with explicit control over accent, language, speaker and fine-grained F0 and energy features. Our proposed model does not rely on bilingual training data. We demonstrate an ability to control synthesized accent for any speaker in an open-source dataset comprising of 7 accents. Human subjective evaluation demonstrates that our model can better retain a speaker's voice and accent quality than controlled baselines while synthesizing fluent speech in all target languages and accents in our dataset.
@inproceedings{badlani23_interspeech,
author={Rohan Badlani and Rafael Valle and Kevin J. Shih and João Felipe Santos and Siddharth Gururani and Bryan Catanzaro},
title={{RAD-MMM: Multilingual Multiaccented Multispeaker Text To Speech}},
year=2023,
booktitle={Proc. INTERSPEECH 2023},
pages={626--630},
doi={10.21437/Interspeech.2023-2330}
}
|
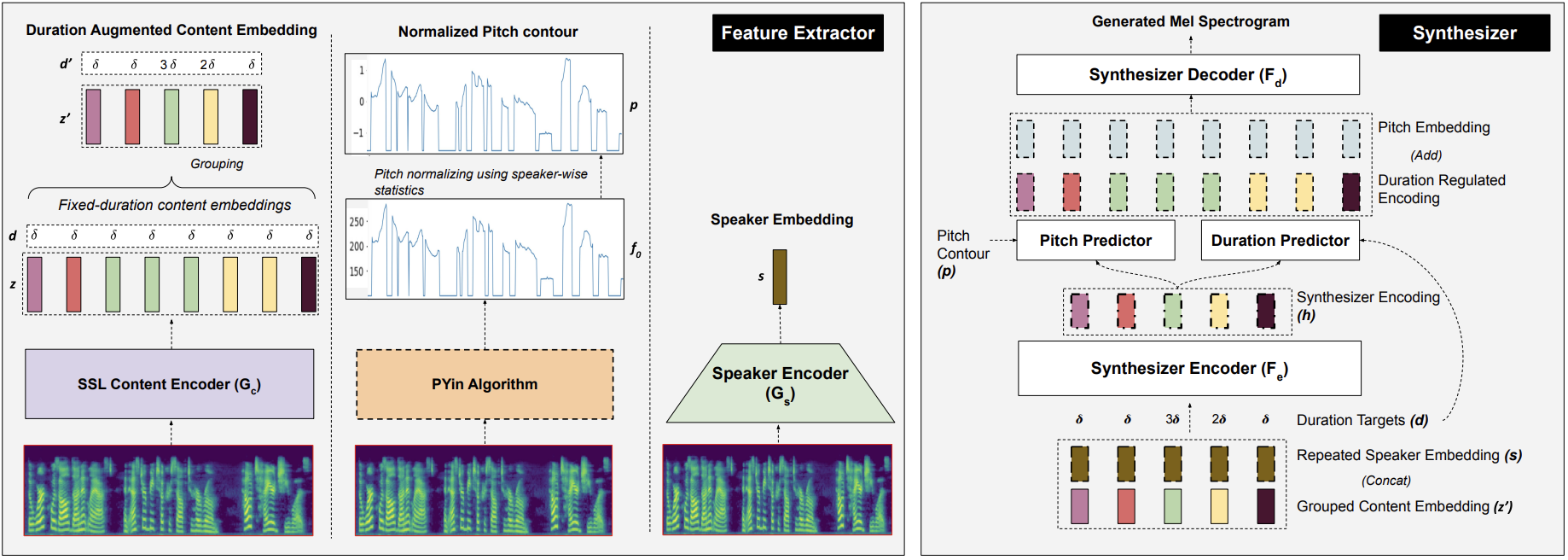 |
pdf |
abstract |
bibtex |
arXiv
We propose SelfVC, a training strategy to iteratively improve a voice conversion model with self-synthesized examples. Previous efforts on voice conversion focus on explicitly disentangling speech representations to separately encode speaker characteristics and linguistic content. However, disentangling speech representations to capture such attributes using task-specific loss terms can lead to information loss by discarding finer nuances of the original signal. In this work, instead of explicitly disentangling attributes with loss terms, we present a framework to train a controllable voice conversion model on entangled speech representations derived from self-supervised learning and speaker verification models. First, we develop techniques to derive prosodic information from the audio signal and SSL representations to train predictive submodules in the synthesis model. Next, we propose a training strategy to iteratively improve the synthesis model for voice conversion, by creating a challenging training objective using self-synthesized examples. In this training approach, the current state of the synthesis model is used to generate voice-converted variations of an utterance, which serve as inputs for the reconstruction task, ensuring a continuous and purposeful refinement of the model. We demonstrate that incorporating such self-synthesized examples during training improves the speaker similarity of generated speech as compared to a baseline voice conversion model trained solely on heuristically perturbed inputs. SelfVC is trained without any text and is applicable to a range of tasks such as zero-shot voice conversion, cross-lingual voice conversion, and controllable speech synthesis with pitch and pace modifications. SelfVC achieves state-of-the-art results in zero-shot voice conversion on metrics evaluating naturalness, speaker similarity, and intelligibility of synthesized audio.
|
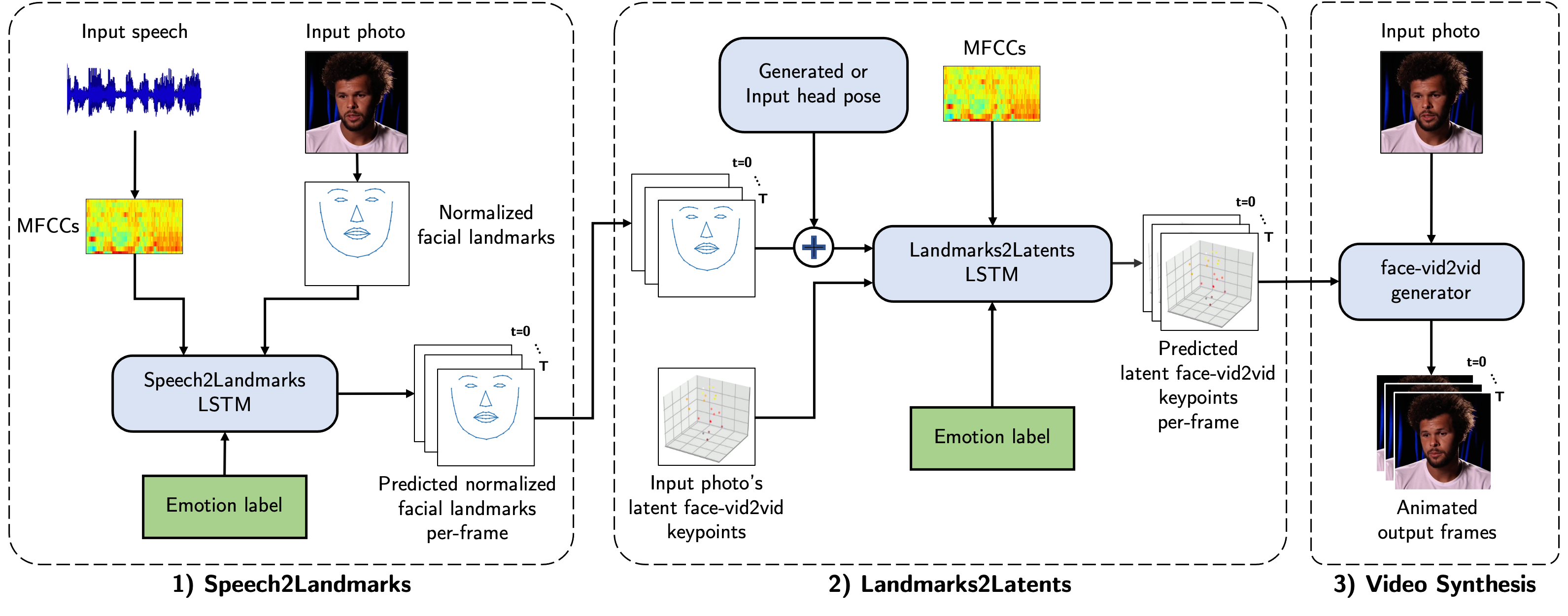
|
pdf |
abstract |
bibtex |
arXiv
Animating portraits using speech has received growing attention in recent years, with various creative and practical use cases. An ideal generated video should have good lip sync with the audio, natural facial expressions and head motions, and high frame quality. In this work, we present SPACE, which uses speech and a single image to generate high-resolution, and expressive videos with realistic head pose, without requiring a driving video. It uses a multi-stage approach, combining the controllability of facial landmarks with the high-quality synthesis power of a pretrained face generator. SPACE also allows for the control of emotions and their intensities. Our method outperforms prior methods in objective metrics for image quality and facial motions and is strongly preferred by users in pair-wise comparisons.
@inproceedings{gururani2023space,
title={SPACE: Speech-driven Portrait Animation with Controllable Expression},
author={Gururani, Siddharth and Mallya, Arun and Wang, Ting-Chun and Valle, Rafael and Liu, Ming-Yu},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={20914--20923},
year={2023}
}
|
|
pdf |
abstract |
bibtex |
code
Recently developed neural-based TTS models have focused on robustness and finer control over acoustic features such as phoneme duration, energy, and F0, allowing users to have some degree of control over the prosody of the generated speech. We propose a model with fine grained attribute control, which also has better acoustic fidelity (attributes of the output which we want to control do not deviate from the control signals) than previously proposed models as shown in our experiments 1 . Unlike other models, our proposed model does not require fine-tuning the vocoder on its outputs, indicating that it generates higher quality mel-spectrograms that are closer to the ground-truth distribution than that of other models.
@inproceedings{valle2023high,
title={High-Acoustic Fidelity Text To Speech Synthesis With Fine-Grained Control Of Speech Attributes},
author={Valle, Rafael and Santos, Jo{\~a}o Felipe and Shih, Kevin J and Badlani, Rohan and Catanzaro, Bryan},
booktitle={ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={1--5},
year={2023},
organization={IEEE}
}
|
|
pdf |
abstract |
bibtex
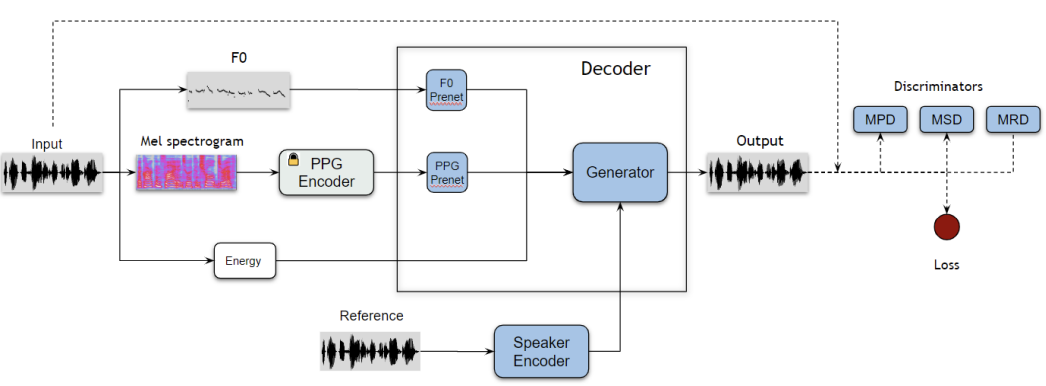
Despite recent advances in voice conversion (VC), it is still challenging to do real-time one-shot voice conversion with good control over timbre and F0. In this work, we present a PPG-based VC model that directly decodes waveforms. We designed a speaker conditioned decoder based on HiFi-GAN, along with a new discriminator that produces high quality audio. Using an F0 prenet and F0 augmented speaker encoder, we are able to control F0 and timbre independently with high fidelity. Our objective and subjective evaluations show that our method is preferred over others in terms of audio quality, timbre similarity and prosody retention.
@inproceedings{kovela2023any,
title={Any-to-Any Voice Conversion with F 0 and Timbre Disentanglement and Novel Timbre Conditioning},
author={Kovela, Sudheer and Valle, Rafael and Dantrey, Ambrish and Catanzaro, Bryan},
booktitle={ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={1--5},
year={2023},
organization={IEEE}
}
|
|
pdf |
abstract |
bibtex |
arXiv |
code
We introduce VANI, a very lightweight multi-lingual accent controllable speech synthesis system. Our model builds upon disentanglement strategies proposed in RADMMM and supports explicit control of accent, language, speaker and fine-grained F0 and energy features for speech synthesis. We utilize the Indic languages dataset, released for LIMMITS 2023 as part of ICASSP Signal Processing Grand Challenge, to synthesize speech in 3 different languages. Our model supports transferring the language of a speaker while retaining their voice and the native accent of the target language. We utilize the large-parameter RADMMM model for Track 1 and lightweight VANI model for Track 2 and 3 of the competition.
@inproceedings{badlani2023vani,
title={VANI: Very-lightweight Accent-controllable TTS for Native and Non-native speakers with Identity Preservation},
author={Badlani, Rohan and Arora, Akshit and Ghosh, Subhankar and Valle, Rafael and Shih, Kevin J and Santos, Jo{\~a}o Felipe and Ginsburg, Boris and Catanzaro, Bryan},
booktitle={ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={1--2},
year={2023},
organization={IEEE}
}
|
|
pdf |
abstract |
bibtex |
arXiv |
code
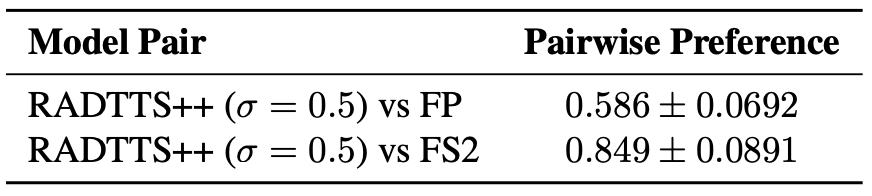
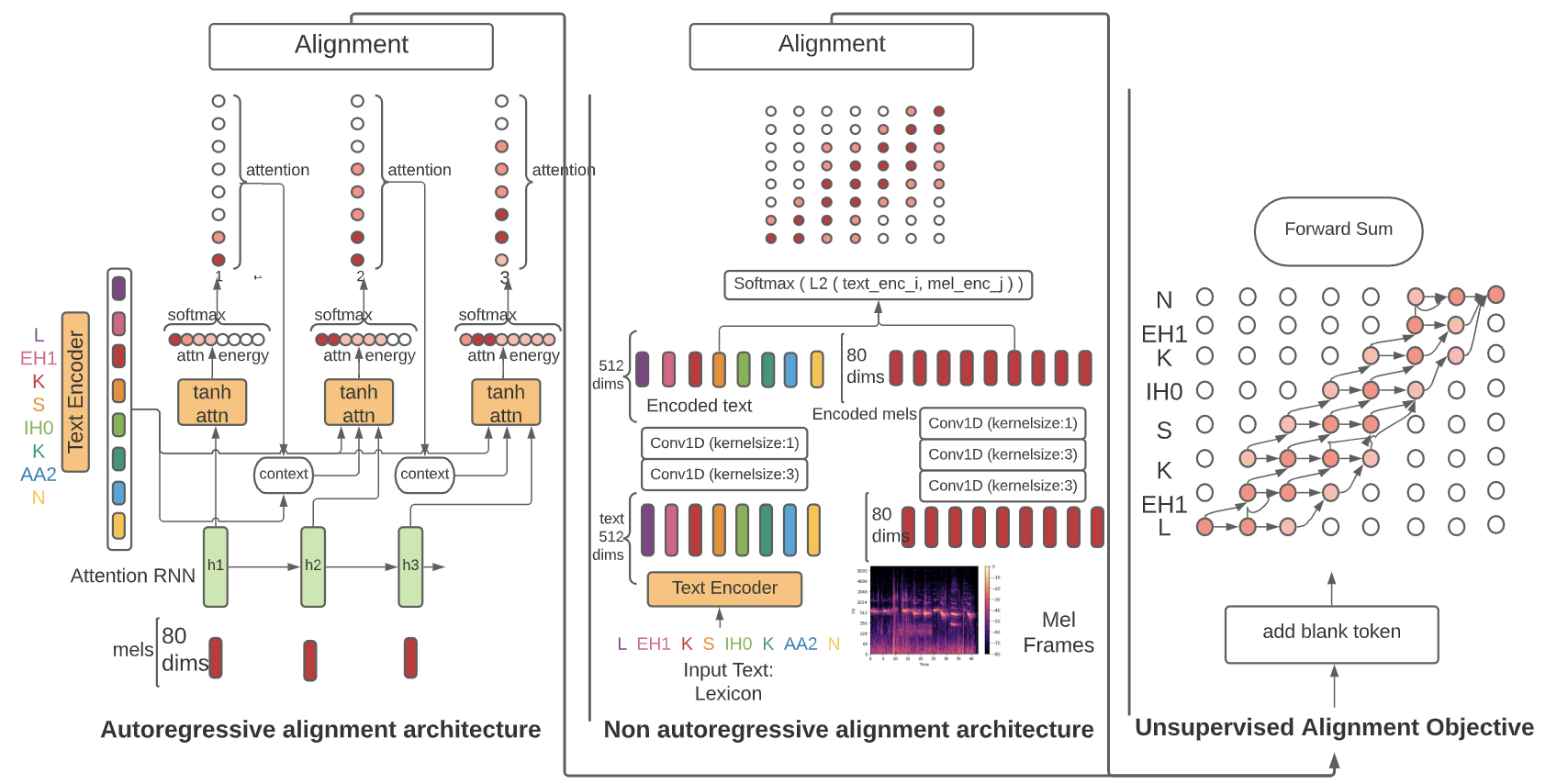
Speech-to-text alignment is a critical component of neural text-to-speech (TTS) models. Autoregressive TTS models typically use an attention mechanism to learn these alignments on-line. However, these alignments tend to be brittle and often fail to generalize to long utterances and out-of-domain text, leading to missing or repeating words. Most non-autoregressive end-to-end TTS models rely on durations extracted from external sources. In this paper we leverage the alignment mechanism proposed in RAD-TTS and demonstrate its applicability to wide variety of neural TTS models. The alignment learning framework combines the forward-sum algorithm, Viterbi algorithm, and an efficient static prior. In our experiments, the framework improves all tested TTS architectures, both autoregressive (Flowtron, Tacotron 2) and non-autoregressive (FastPitch, FastSpeech 2, RAD-TTS). Specifically, it improves alignment convergence speed, simplifies the training pipeline by eliminating need for external aligners, enhances robustness to errors on long utterances and improves the perceived speech synthesis quality, as judged by human evaluators.
@inproceedings{badlani2022one,
title={One TTS alignment to rule them all},
author={Badlani, Rohan and {\L}a{\'n}cucki, Adrian and Shih, Kevin J and Valle, Rafael and Ping, Wei and Catanzaro, Bryan},
booktitle={ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={6092--6096},
year={2022},
organization={IEEE}
}
|
|
pdf |
abstract |
bibtex |
arXiv |
code
Despite recent advances in generative modeling for text-to-speech synthesis, these models do not yet have the same fine-grained adjustability of pitch-conditioned deterministic models such as FastPitch and FastSpeech2. Pitch information is not only low-dimensional, but also discontinuous, making it particularly difficult to model in a generative setting. Our work explores several techniques for handling the aforementioned issues in the context of Normalizing Flow models. We also find this problem to be very well suited for Neural Spline flows, which is a highly expressive alternative to the more common affine-coupling mechanism in Normalizing Flows.
@article{shih2022generative,
title={Generative modeling for low dimensional speech attributes with neural spline flows},
author={Shih, Kevin J and Valle, Rafael and Badlani, Rohan and Santos, Jo{\~a}o Felipe and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2203.01786},
year={2022}
}
|
|
|
pdf |
abstract |
bibtex |
code
This work introduces a predominantly parallel, end-to-end TTS model based on normalizing flows. It extends prior parallel approaches by additionally modeling speech rhythm as a separate generative distribution to facilitate variable token duration during inference. We further propose a robust framework for the on-line extraction of speech-text alignments – a critical yet highly unstable learning problem in end-to-end TTS frameworks. Our experiments demonstrate that our proposed techniques yield improved alignment quality, better output diversity compared to controlled baselines.
@inproceedings{shih2021rad,
title={RAD-TTS: Parallel flow-based TTS with robust alignment learning and diverse synthesis},
author={Shih, Kevin J and Valle, Rafael and Badlani, Rohan and Lancucki, Adrian and Ping, Wei and Catanzaro, Bryan},
booktitle={ICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models},
year={2021}
}
|
|
|
pdf |
abstract |
bibtex |
arXiv |
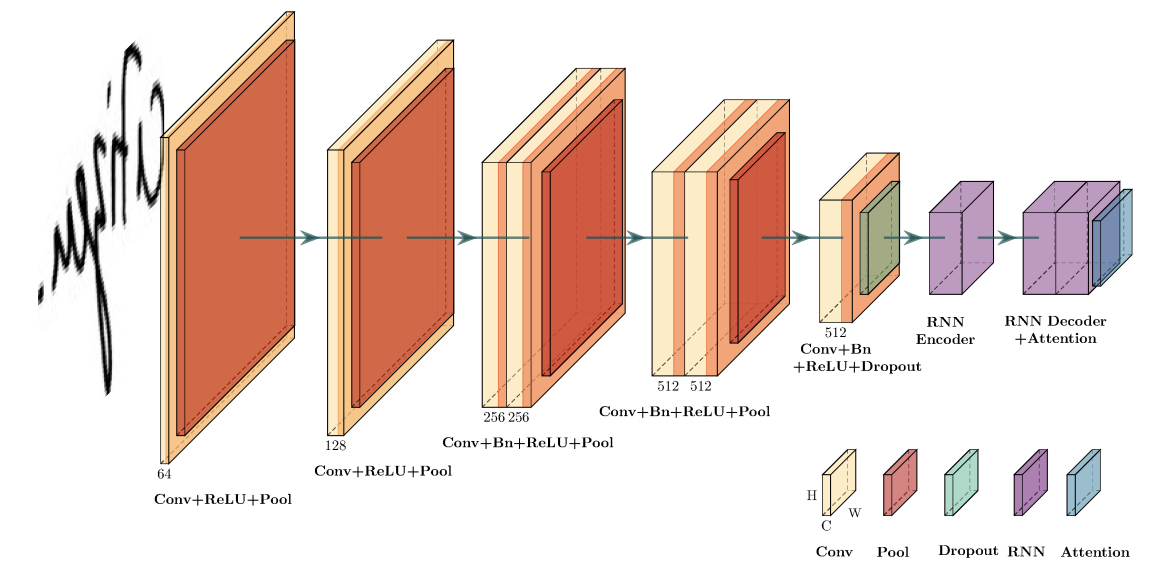
The paper approaches the task of handwritten text recognition (HTR) with attentional encoder-decoder networks trained on sequences of characters, rather than words. We experiment on lines of text from popular handwriting datasets and compare different activation functions for the attention mechanism used for aligning image pixels and target characters. We find that softmax attention focuses heavily on individual characters, while sigmoid attention focuses on multiple characters at each step of the decoding. When the sequence alignment is one-to-one, softmax attention is able to learn a more precise alignment at each step of the decoding, whereas the alignment generated by sigmoid attention is much less precise. When a linear function is used to obtain attention weights, the model predicts a character by looking at the entire sequence of characters and performs poorly because it lacks a precise alignment between the source and target. Future research may explore HTR in natural scene images, since the model is capable of transcribing handwritten text without the need for producing segmentations or bounding boxes of text in images.
@article{poulos2021character,
title={Character-based handwritten text transcription with attention networks},
author={Poulos, Jason and Valle, Rafael},
journal={Neural Computing and Applications},
volume={33},
number={16},
pages={10563--10573},
year={2021},
publisher={Springer}
}
|
|
abstract
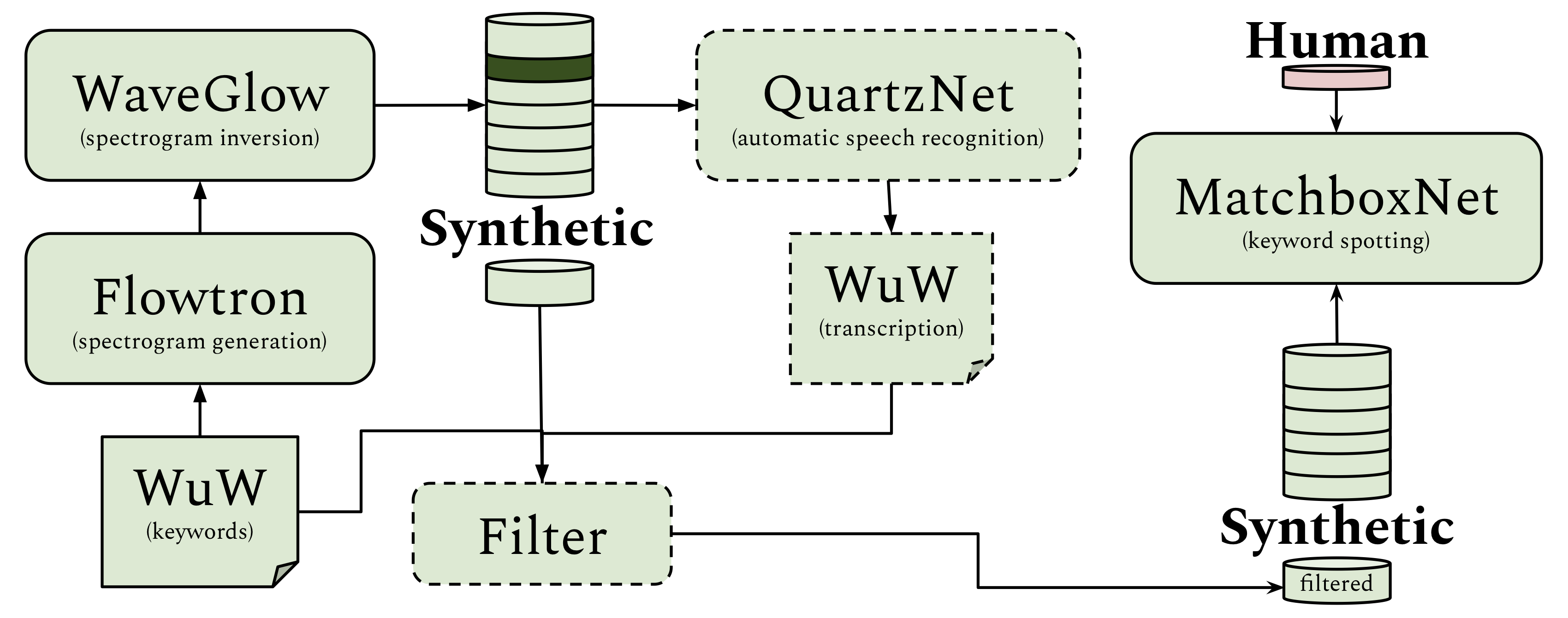
In this paper we describe a method that uses text-to-speech (TTS) synthesis models to improve the quality of keyword spotting models and to reduce the time and money required to train them. We synthesize varied data from different speakers by combining Flowtron, a multispeaker text-to-mel-spectrogram synthesis model producing speech with high variance, and WaveGlow, a universal mel-spectrogram to audio model. We fine-tune the synthetic data by using QuartzNet, an automatic speech recognition model, to find and remove samples with skipped, repeated and mispronounced words. With this fine-tuned synthetic data and 10% of human data we are able to achieve keyword spotting scores (accuracy and F1) that are comparable to using the full human dataset. We provide results on binary and multiclass Wake-up-Word datasets, including the Speech Commands Dataset. |
|
|
pdf |
samples |
abstract
In our recent paper, we propose Flowtron: an autoregressive flow-based generative network for text-to-speech synthesis with control over speech variation and style transfer. Flowtron combines insights from IAF and optimizes Tacotron 2 in order to provide high-quality and controllable mel-spectrogram synthesis. |

|
pdf |
abstract
We propose a novel approach for image segmentation that combines Neural Ordinary Differential Equations (NODEs) and the Level Set method. Our approach parametrizes the evolution of an initial contour with a NODE that implicitly learns from data a speed function describing the evolution. In addition, for cases where an initial contour is not available and to alleviate the need for careful choice or design of contour embedding functions, we propose a NODE-based method that evolves an image embedding into a dense per-pixel semantic label space. We evaluate our methods on kidney segmentation (KiTS19) and on salient object detection (PASCAL-S, ECSSD and HKU-IS). In addition to improving initial contours provided by deep learning models while using a fraction of their number of parameters, our approach achieves F scores that are higher than several state-of-the-art deep learning algorithms |
|
|
pdf |
samples |
abstract
Mellotron is a multispeaker voice synthesis model based on Tacotron 2 GST that can make a voice emote and sing without emotive or singing training data. By explicitly conditioning on rhythm and continuous pitch contours from an audio signal or music score, Mellotron is able to generate speech in a variety of styles ranging from read speech to expressive speech, from slow drawls to rap and from monotonous voice to singing voice. |
|
|
pdf |
samples |
abstract
We propose WaveGlow: a flow-based network capable of generating high quality speech from mel-spectrograms. WaveGlow combines insights from Glow and WaveNet in order to provide fast, efficient and high-quality audio synthesis, without the need for auto-regression. WaveGlow is implemented using only a single network, trained using only a single cost function: maximizing the likelihood of the training data, which makes the training procedure simple and stable. |
|
pdf |
abstract
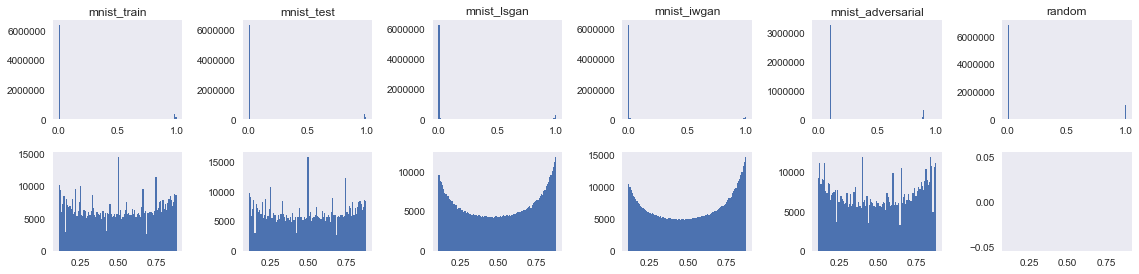
In this paper we show strategies to easily identify fake samples generated with the Generative Adversarial Network framework. One strategy is based on the statistical analysis and comparison of raw pixel values and features extracted from them. The other strategy learns formal specifications from the real data and shows that fake samples violate the specifications of the real data. We show that fake samples produced with GANs have a universal signature that can be used to identify fake samples. We provide results on MNIST, CIFAR10, music and speech data. |
|
pdf |
abstract |
code
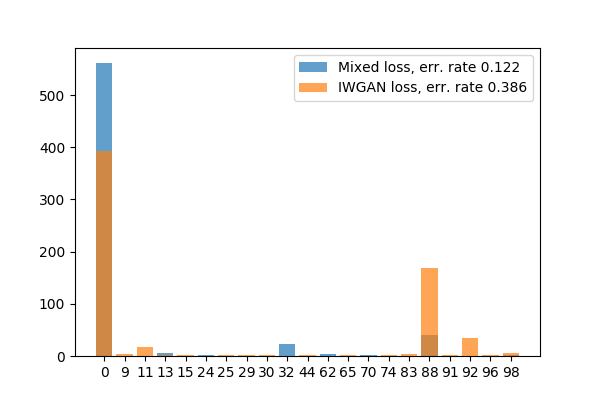
In this paper we investigate the ability of generative adversarial networks (GANs) to synthesize spoofing attacks on modern speaker recognition systems. We first show that samples generated with SampleRNN and WaveNet are unable to fool a CNN-based speaker recognition system. We propose a modification of the Wasserstein GAN objective function to make use of data that is real but not from the class being learned. Our semi-supervised learning method is able to perform both targeted and untargeted attacks, raising questions related to security in speaker authentication systems. |
|
github |
abstract |
audio
In this paper we investigate the generation of sequences using generative adversarial networks (GANs). We open the paper by providing a brief introduction to sequence generation and challenges in GANs. We briefly describe encoding strategies for text and MIDI data in light of their use with convolutional architectures. In our experiments we consider the unconditional generation of polyphonic and monophonic piano roll generation as well as short sequences. For each data type, we provide sonic or text examples of generated data, interpolation in the latent space and vector arithmetic. |
|
|
pdf |
abstract |
bibtex |
arXiv |
code
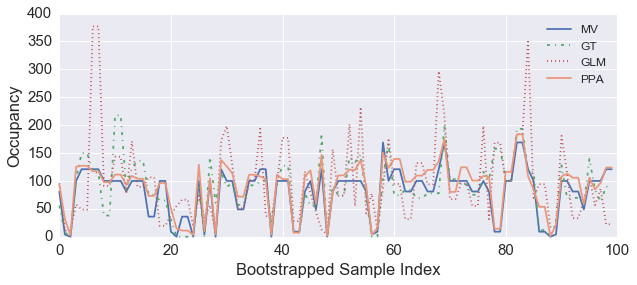
This paper outlines preliminary steps towards the development of an audio based room-occupancy analysis model. Our approach borrows from speech recognition tradition and is based on Gaussian Mixtures and Hidden Markov Models. We analyze possible challenges encountered in the development of such a model, and offer several solutions including feature design and prediction strategies. We provide results obtained from experiments with audio data from a retail store in Palo Alto, California. Model assessment is done via leave-two-out Bootstrap and model convergence achieves good accuracy, thus representing a contribution to multimodal people counting algorithms.
@article{valle2016abroa,
title={ABROA: Audio-Based Room-Occupancy Analysis using Gaussian Mixtures and Hidden Markov Models},
author={Valle, Rafael},
journal={arXiv preprint arXiv:1607.07801},
year={2016}
}
|
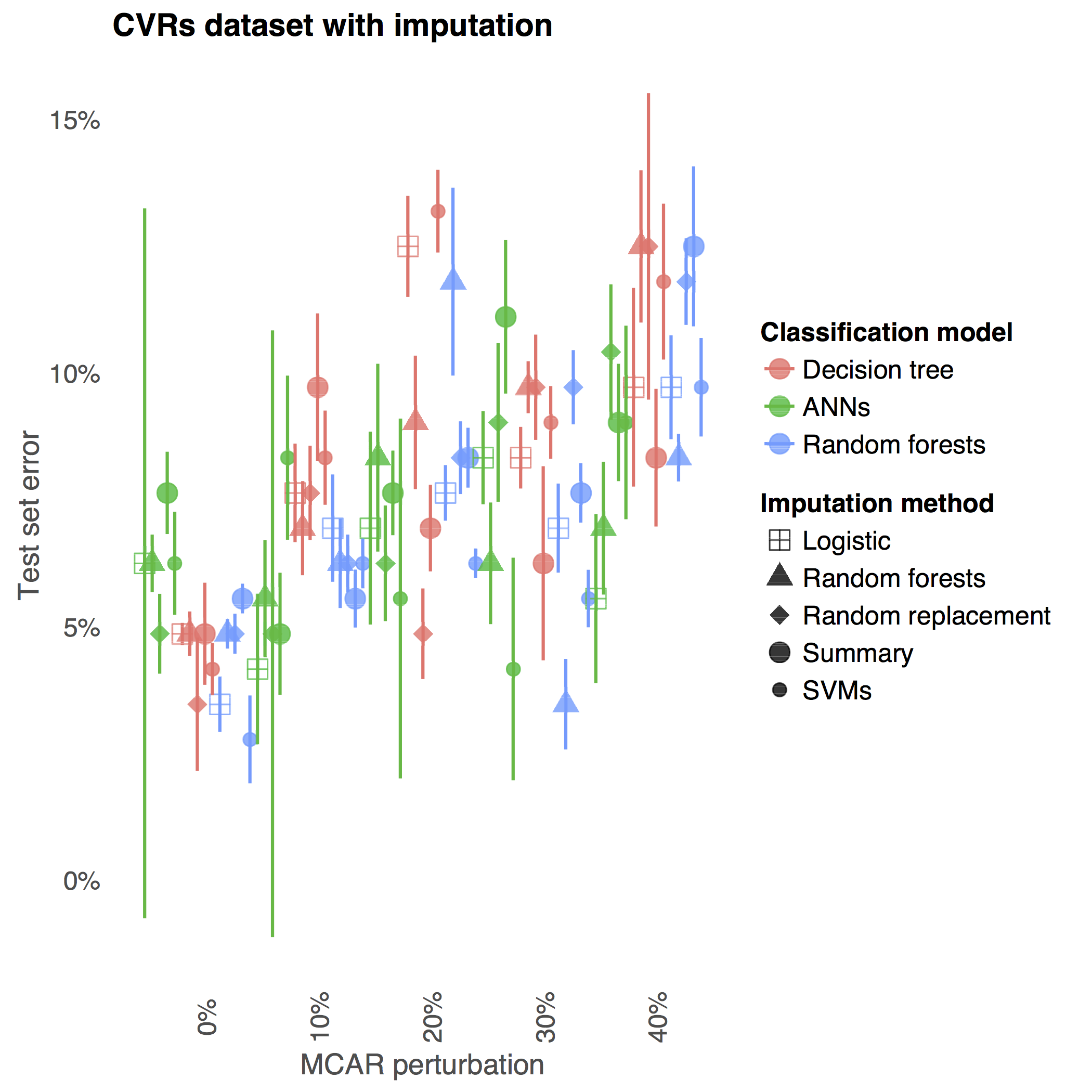
|
pdf |
abstract |
bibtex |
arXiv |
code
This paper compares methods for imputing missing categorical data for supervised learning tasks. The ability of researchers to accurately fit a model and yield unbiased estimates may be compromised by missing data, which are prevalent in survey-based social science research. We experiment on two machine learning benchmark datasets with missing categorical data, comparing classifiers trained on non-imputed (i.e., one-hot encoded) or imputed data with different degrees of missing data perturbation. The results show imputation methods can increase predictive accuracy in the presence of missing-data perturbation. Additionally, we find that for imputed models, missing data perturbation can improve prediction accuracy by regularizing the classifier.
@article{poulos2016missing,
title={Missing Data Imputation for Supervised Learning},
author={Poulos, Jason and Valle, Rafael},
journal={arXiv preprint arXiv:1610.09075},
year={2016}
}
|
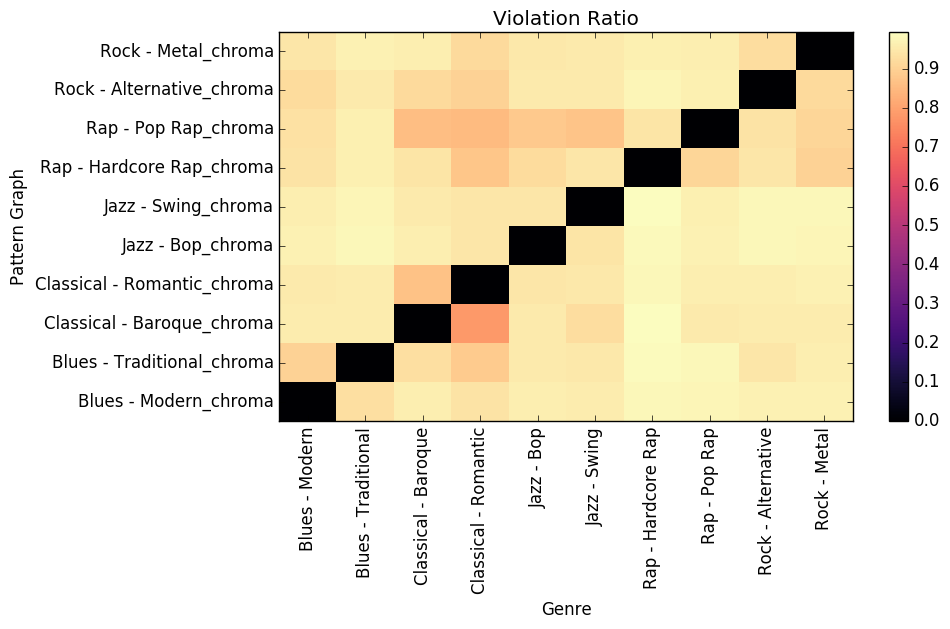
|
pdf |
abstract |
bibtex |
code
We describe a system to learn and visualize specifications from song(s) in symbolic and audio formats. The core of our approach is based on a software engineering procedure called specification mining. Our procedure extracts patterns from feature vectors and uses them to build pattern graphs. The feature vectors are created by segmenting song(s) and extracting time and and frequency domain features from them, such as chromagrams, chord degree and interval classification. The pattern graphs built on these feature vectors provide the likelihood of a pattern between nodes, as well as start and ending nodes. The pattern graphs learned from a song(s) describe formal specifications that can be used for human interpretable quantitatively and qualitatively song comparison or to perform supervisory control in machine improvisation. We offer results in song summarization, song and style validation and machine improvisation with formal specifications.
@inproceedings{valle2016learning,
title={Learning and Visualizing Music Specifications using Pattern Graphs},
author={Valle, Rafael and Fremont, Daniel J and Akkaya, Ilge and Donze, Alexandre and Freed, Adrian and Seshia, Sanjit S},
booktitleaddon= {Proceedings of the Seventeenth ISMIR Conference}
booktitle={ISMIR},
year={2016}
}
|
![[NEW]](images/new.png)